En el mundo actual impulsado por los datos, la precisión y confiabilidad de los mismos son primordiales. Las organizaciones dependen de datos limpios y precisos para diversos fines, desde la gestión de relaciones con clientes hasta la inteligencia empresarial y el análisis. Uno de los aspectos críticos de la calidad de los datos es asegurarse de que los nombres y las direcciones estén formateados y estandarizados correctamente. En este blog, exploraremos los desafíos y las mejores prácticas para lograr una limpieza de datos de alta precisión a través de transformaciones avanzadas de nombres y direcciones.
Introducción
La limpieza de datos, también conocida como depuración de datos o limpieza de datos, es el proceso de identificar y corregir errores e inconsistencias en conjuntos de datos. Esta práctica es esencial para mantener la calidad y la integridad de los datos, ya que datos inexactos o inconsistentes pueden llevar a errores costosos y decisiones desinformadas. Entre los problemas más comunes de calidad de datos se encuentran las discrepancias en los nombres y las direcciones.
La Importancia de los Nombres y Direcciones
Los nombres y las direcciones son puntos de datos fundamentales utilizados en varios procesos comerciales, como la comunicación con el cliente, la logística de entrega y la segmentación de mercado. Asegurar que estos elementos de datos sean precisos y estandarizados es crucial para:
- Gestión de Relaciones con Clientes (CRM): Nombres y direcciones precisos de los clientes son esenciales para construir relaciones sólidas y ofrecer experiencias personalizadas.
- Marketing Directo: Las campañas de marketing dependen de datos de dirección precisos para dirigirse a la audiencia correcta y reducir los costos de marketing.
- Comercio Electrónico: La información precisa de envío es fundamental para entregar productos a tiempo y reducir las tasas de devolución.
- Prevención de Fraudes: Verificar la identidad de los clientes basándose en nombres y direcciones es crucial para detectar actividades fraudulentas.
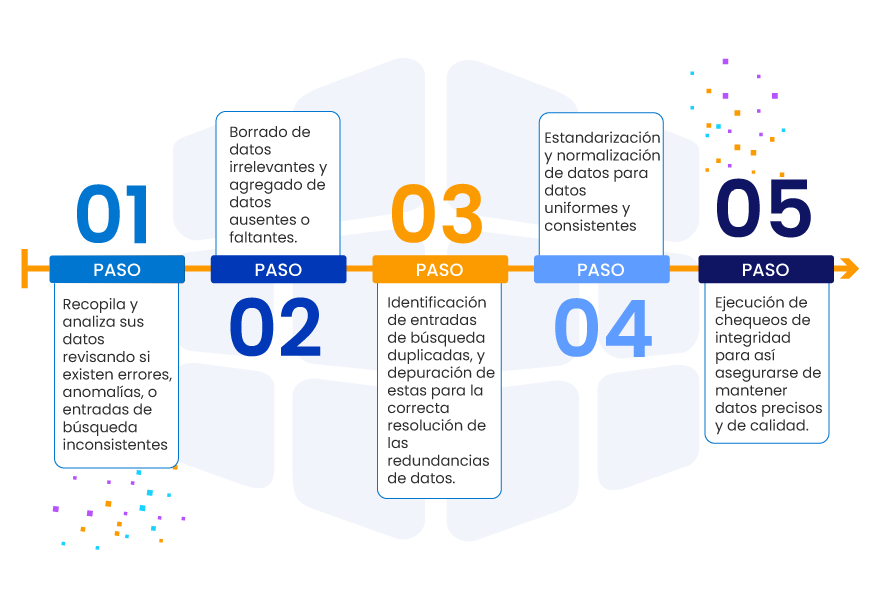
Lograr una limpieza de datos de alta precisión en el contexto de nombres y direcciones implica superar varios desafíos e implementar las mejores prácticas. Sumergámonos en estos aspectos en detalle.
Desafíos en la Limpieza de Datos para Nombres y Direcciones
- Variabilidad de Datos: Los nombres y las direcciones pueden ser altamente variables debido a diferencias culturales, abreviaturas y preferencias personales. Por ejemplo, «Robert Smith» puede registrarse como «Bob Smith» o «R. Smith,» y «123 Main Street» puede aparecer como «123 Main St» o «123 Main St.»
- Consideraciones Internacionales: Para las organizaciones con presencia global, tratar con direcciones internacionales puede ser complejo. Diferentes países tienen formatos de dirección, códigos postales y conjuntos de caracteres variados, lo que dificulta la estandarización.
- Volumen de Datos: Procesar grandes volúmenes de datos de manera rápida y precisa es un desafío significativo, especialmente para organizaciones con extensas bases de datos de clientes o plataformas en línea con un alto tráfico de usuarios.
- Orígenes de Datos: Los datos pueden provenir de múltiples fuentes, incluida la entrada del cliente, formularios en línea y bases de datos de terceros. Cada fuente puede introducir su propio conjunto de errores e inconsistencias.
- Privacidad y Seguridad de Datos: Manejar información sensible como nombres y direcciones requiere un estricto cumplimiento de las regulaciones de protección de datos, lo que agrega complejidad a los procesos de limpieza de datos.
Mejores Prácticas para Alcanzar una Limpieza de Datos de Alta Precisión
Para abordar los desafíos mencionados anteriormente y lograr una limpieza de datos de alta precisión, las organizaciones pueden implementar las siguientes mejores prácticas:
Estandarización de Datos
La estandarización es la base de una limpieza de datos precisa. Involucra normalizar los datos a un formato consistente, independientemente de su fuente u origen. Aquí hay algunos pasos a considerar:
Estandarización de Nombres
- Análisis Gramatical: Descomponga los nombres en partes constituyentes como nombre, segundo nombre, apellido y sufijo. Esto ayuda a abordar la variabilidad.
- Normalización de Mayúsculas y Minúsculas: Convierta los nombres a un formato estándar (por ejemplo, mayúsculas iniciales) para garantizar uniformidad.
- Expansión de Abreviaturas: Expanda las abreviaturas comunes, como «Dr.» a «Doctor,» para eliminar variaciones.
- Manejo de Caracteres Especiales: Aborde diacríticos, acentos y caracteres especiales para garantizar la compatibilidad entre sistemas.
Estandarización de Direcciones
- Unificación de Formato: Convierta las direcciones a un formato estandarizado, teniendo en cuenta las reglas específicas del país y las convenciones de códigos postales.
- Expansión de Abreviaturas: Amplíe las abreviaturas de sufijos de calles (por ejemplo, «St.» a «Street») para mayor consistencia.
- Geocodificación: Utilice servicios de geocodificación para validar y mejorar los datos de dirección mediante la adición de coordenadas de latitud y longitud.
Validación de Datos
La validación asegura que los datos no solo estén estandarizados, sino que también sean precisos y completos. Aquí hay algunas técnicas de validación:
Validación de Nombres
- Bases de Datos de Referencia: Utilice bases de datos de referencia para validar nombres frente a una lista de nombres comunes y alias conocidos.
- Coincidencia de Patrones: Emplee expresiones regulares y coincidencia de patrones para identificar y marcar nombres potencialmente inválidos.
Validación de Direcciones
- Verificación de Direcciones Postales: Utilice servicios de verificación de direcciones postales para validar direcciones frente a bases de datos postales oficiales.
- Validación Geoespacial: Valide las ubicaciones de las direcciones mediante datos geoespaciales para garantizar que existan y estén correctamente ubicadas.
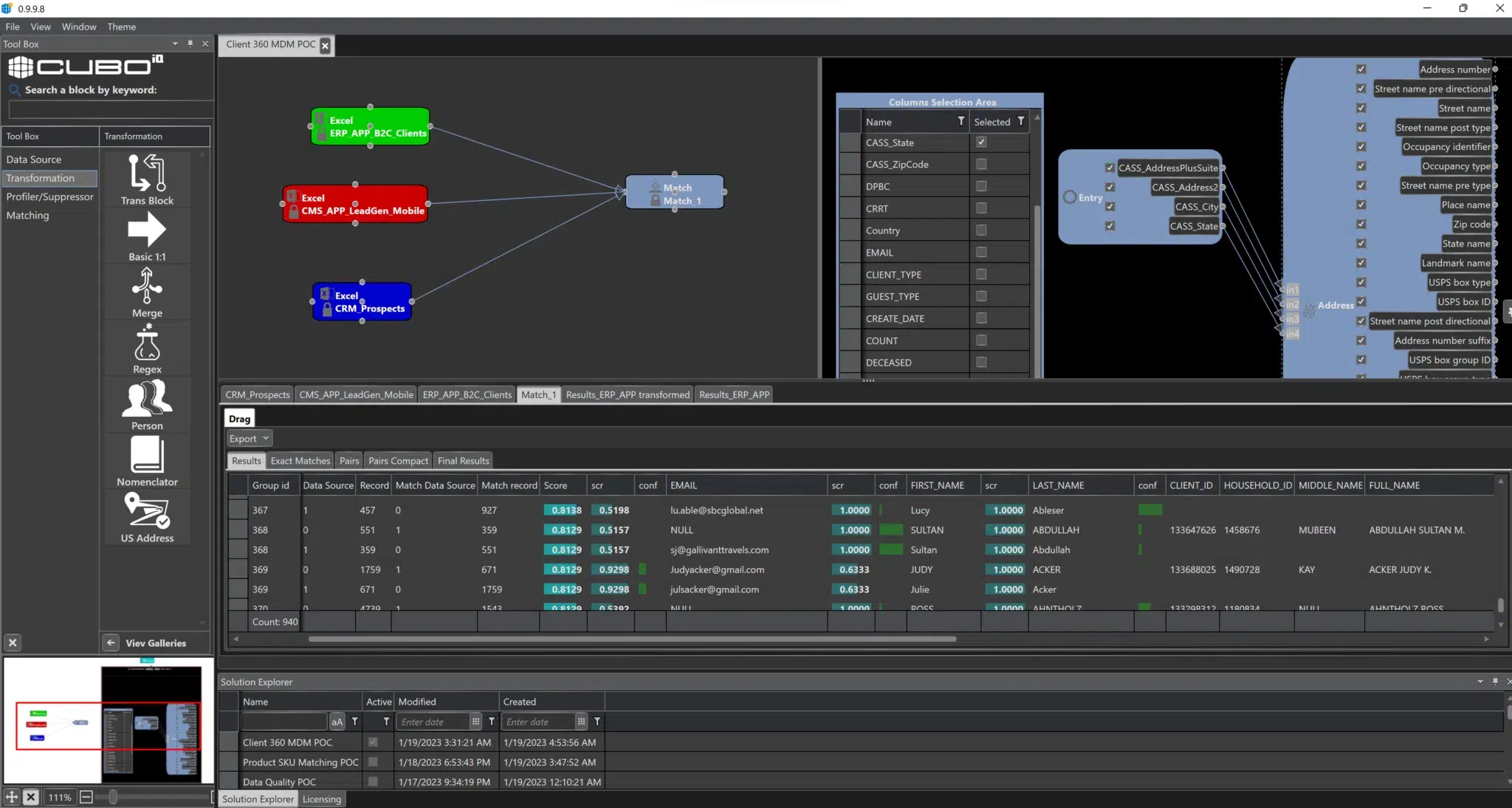
Coincidencia Difusa
Las técnicas de coincidencia difusa son valiosas para identificar nombres y direcciones similares que pueden tener ligeras variaciones debido a errores al ingresar los datos. Estos métodos utilizan algoritmos para comparar y coincidir puntos de datos en función de su similitud.
Coincidencia Difusa de Nombres
- Coincidencia de Soundex: Los algoritmos Soundex agrupan nombres por su similitud fonética, lo que ayuda a identificar nombres que suenan de manera similar.
- Distancia de Levenshtein: Calcule la distancia de Levenshtein entre nombres para medir su similitud basada en cambios a nivel de caracteres.
Coincidencia Difusa de Direcciones
- Coincidencia Basada en Tokens: Divida las direcciones en tokens (palabras o elementos) y compárelos en busca de similitudes para identificar posibles coincidencias.
- Proximidad Geoespacial: Compare las ubicaciones de las direcciones en función de la proximidad para determinar posibles coincidencias.
Enriquecimiento de Datos
El enriquecimiento de datos implica agregar información adicional a los datos existentes para mejorar su precisión y completitud. Esto puede ser especialmente valioso para nombres y direcciones.
Enriquecimiento de Nombres
- Predicción de Género: Utilice algoritmos basados en nombres para predecir el género probable asociado con un nombre, lo que puede ser útil para la comunicación personalizada.
- Origen del Nombre: Determine el origen o la etnia asociada con un nombre para mejorar las estrategias de marketing.
Enriquecimiento de Direcciones
- Geocodificación: Mejore las direcciones con información geoespacial, como latitud, longitud y proximidad a puntos de referencia o lugares de interés.
- Datos Demográficos: Agregue datos demográficos a las direcciones para una mejor segmentación y orientación de clientes.
Privacidad de Datos y Cumplimiento
Asegurar la privacidad de los datos y cumplir con las regulaciones pertinentes es fundamental. Aquí hay pasos esenciales a seguir:
Gestión de Consentimiento
- Consentimiento Explícito: Obtenga el consentimiento explícito de las personas para utilizar su información personal, especialmente para fines de marketing y comunicación.
- Políticas de Retención de Datos: Implemente políticas de retención de datos para garantizar que los datos no se conserven más tiempo del necesario.
Encriptación de Datos
- Datos en Tránsito: Encripte los datos cuando se transmitan entre sistemas o se almacenen en la nube para protegerlos contra el acceso no autorizado.
- Datos en Reposo: Encripte los datos almacenados para protegerlos contra violaciones o robos.
Auditorías de Cumplimiento
- Auditorías Regulares: Realice auditorías periódicas de las actividades de procesamiento de datos para asegurarse de que se cumplan las regulaciones de protección de datos.
- Capacitación: Capacite a los empleados en las mejores prácticas de privacidad de datos para minimizar el riesgo de violaciones de datos.
Escalabilidad y Rendimiento
Manejar grandes volúmenes de datos de manera eficiente es crucial para las organizaciones con conjuntos de datos extensos. Considere estas prácticas:
Optimización de la Tubería de Datos
- Procesamiento Paralelo: Implemente técnicas de procesamiento paralelo para depurar los datos más rápido distribuyendo tareas en múltiples núcleos o servidores.
- Procesamiento en Tiempo Real: Utilice el procesamiento en tiempo real para la depuración de datos en tiempo real, lo que es fundamental para las plataformas en línea.
Monitoreo de la Calidad de Datos
- Tablero de Control y Alertas: Configure tableros de control y alertas para monitorear la calidad de los datos en tiempo real e identificar problemas de manera rápida.
- Procesamiento por Lotes: Programme trabajos de procesamiento por lotes durante las horas de menor actividad para minimizar la carga del sistema.
Conclusión
Alcanzar una limpieza de datos de alta precisión a través de transformaciones avanzadas de nombres y direcciones es esencial para que las organizaciones mantengan la calidad de los datos, mejoren la eficiencia operativa y tomen decisiones informadas. Al abordar los desafíos de la variabilidad de los datos, las consideraciones internacionales, el volumen de datos, las fuentes de datos y las preocupaciones de privacidad, e implementar mejores prácticas como la estandarización de datos, la validación, la coincidencia difusa, el enriquecimiento de datos, el cumplimiento, la escalabilidad y la optimización del rendimiento, las organizaciones pueden garantizar que sus datos de nombres y direcciones estén limpios, precisos y confiables.
En la era de los datos grandes y la analítica, la calidad de sus datos puede tener un impacto significativo en el éxito de su negocio. Por lo tanto, invertir en prácticas sólidas de limpieza de datos es una decisión estratégica que puede generar retornos sustanciales en términos de mejores experiencias para el cliente, ahorro de costos y ventaja competitiva.
Para más información: https://revistaingenieria.univalle.edu.co/index.php/ingenieria_y_competitividad/article/view/11361
Te deseamos mucho éxito y no te pierdas nuestros útiles consejos sobre las pruebas de limpieza de datos que estaremos subiendo a nuestro canal de youtube https://www.youtube.com/@DatosMaestrosLATAM ¡Esperamos poder ayudarte a alcanzar tus metas con las pruebas de limpieza de datos con nuestros servicios y combinado con CUBO iQ® PlataForma de auditoria de calidad de datos sobre limpieza de datos con un enfoque no invasivo de software de limpieza de datos! ???
También puedes comunicarte con nosotros si tienes preguntas relacionadas con este documento o si deseas discutir sobre tu iniciativa de las pruebas de limpieza de datos. Escríbenos a contacto@datosmaestros.com o agenda aqui sin compromiso.
![]()